This is a belated response to a Math-Overflow exchange between Thomas Riepe and Chandan Singh Dalawat asking for a possible connection between Connes’ noncommutative geometry approach to the Riemann hypothesis and the Langlands program.
Here’s the punchline : a large chunk of the Connes-Marcolli book Noncommutative Geometry, Quantum Fields and Motives can be read as an exploration of the noncommutative boundary to the Langlands program (at least for $GL_1 $ and $GL_2 $ over the rationals $\mathbb{Q} $).
Recall that Langlands for $GL_1 $ over the rationals is the correspondence, given by the Artin reciprocity law, between on the one hand the abelianized absolute Galois group
$Gal(\overline{\mathbb{Q}}/\mathbb{Q})^{ab} = Gal(\mathbb{Q}(\mu_{\infty})/\mathbb{Q}) \simeq \hat{\mathbb{Z}}^* $
and on the other hand the connected components of the idele classes
$\mathbb{A}^{\ast}_{\mathbb{Q}}/\mathbb{Q}^{\ast} = \mathbb{R}^{\ast}_{+} \times \hat{\mathbb{Z}}^{\ast} $
The locally compact Abelian group of idele classes can be viewed as the nice locus of the horrible quotient space of adele classes $\mathbb{A}_{\mathbb{Q}}/\mathbb{Q}^{\ast} $. There is a well-defined map
$\mathbb{A}_{\mathbb{Q}}’/\mathbb{Q}^{\ast} \rightarrow \mathbb{R}_{+} \qquad (x_{\infty},x_2,x_3,\ldots) \mapsto | x_{\infty} | \prod | x_p |_p $
from the subset $\mathbb{A}_{\mathbb{Q}}’ $ consisting of adeles of which almost all terms belong to $\mathbb{Z}_p^{\ast} $. The inverse image of this map over $\mathbb{R}_+^{\ast} $ are precisely the idele classes $\mathbb{A}^{\ast}_{\mathbb{Q}}/\mathbb{Q}^{\ast} $. In this way one can view the adele classes as a closure, or ‘compactification’, of the idele classes.
This is somewhat reminiscent of extending the nice action of the modular group on the upper-half plane to its badly behaved action on the boundary as in the Manin-Marcolli cave post.
The topological properties of the fiber over zero, and indeed of the total space of adele classes, are horrible in the sense that the discrete group $\mathbb{Q}^* $ acts ergodically on it, due to the irrationality of $log(p_1)/log(p_2) $ for primes $p_i $. All this is explained well (in the semi-local case, that is using $\mathbb{A}_Q’ $ above) in the Connes-Marcolli book (section 2.7).
In much the same spirit as non-free actions of reductive groups on algebraic varieties are best handled using stacks, such ergodic actions are best handled by the tools of noncommutative geometry. That is, one tries to get at the geometry of $\mathbb{A}_{\mathbb{Q}}/\mathbb{Q}^{\ast} $ by studying an associated non-commutative algebra, the skew-ring extension of the group-ring of the adeles by the action of $\mathbb{Q}^* $ on it. This algebra is known to be Morita equivalent to the Bost-Connes algebra which is the algebra featuring in Connes’ approach to the Riemann hypothesis.
It shouldn’t thus come as a major surprise that one is able to recover the other side of the Langlands correspondence, that is the Galois group $Gal(\mathbb{Q}(\mu_{\infty})/\mathbb{Q}) $, from the Bost-Connes algebra as the symmetries of certain states.
In a similar vein one can read the Connes-Marcolli $GL_2 $-system (section 3.7 of their book) as an exploration of the noncommutative closure of the Langlands-space $GL_2(\mathbb{A}_{\mathbb{Q}})/GL_2(\mathbb{Q}) $.
At the moment I’m running a master-seminar noncommutative geometry trying to explain this connection in detail. But, we’re still in the early phases, struggling with the topology of ideles and adeles, reciprocity laws, L-functions and the lot. Still, if someone is interested I might attempt to post some lecture notes here.
6 Comments However, as
However, as  We have seen that
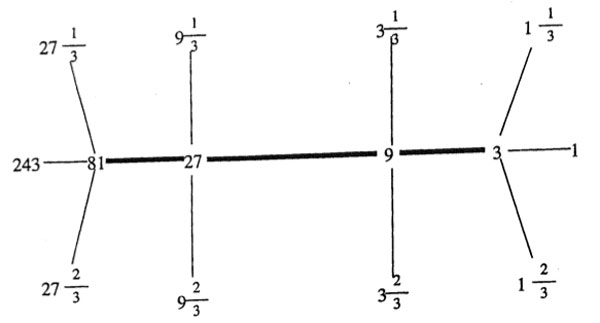
We have seen that 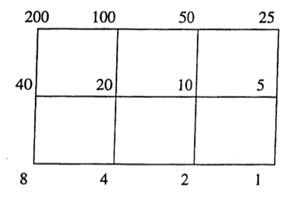 As $\Gamma_0(N) $ fixes $L_1 $ and $L_N $ it also fixes all lattices in the (N|1)-thread, that is all lattices occurring in a shortest path from $L_1 $ to $L_N $ (on the left a picture of the (200|1)-thread).
As $\Gamma_0(N) $ fixes $L_1 $ and $L_N $ it also fixes all lattices in the (N|1)-thread, that is all lattices occurring in a shortest path from $L_1 $ to $L_N $ (on the left a picture of the (200|1)-thread). Most of the moonshine groups are of the form $\Gamma_0(n|h)+e,f,g,… $ for some $N=h.n $ such that $h | 24 $ and $h^2 | N $. The group $\Gamma_0(n|h) $ is then conjugate to the modular subgroup $\Gamma_0(\frac{n}{h}) $ by the element $\begin{bmatrix} h & 0 \ 0 & 1 \end{bmatrix} $. With $\Gamma_0(n|h)+e,f,g,… $ we mean that the group $\Gamma_0(n|h) $ is extended with the involutions $W_e,W_f,W_g,… $. If we simply add all Atkin-Lehner involutions we write $\Gamma_0(n|h)+ $ for the resulting group.
Most of the moonshine groups are of the form $\Gamma_0(n|h)+e,f,g,… $ for some $N=h.n $ such that $h | 24 $ and $h^2 | N $. The group $\Gamma_0(n|h) $ is then conjugate to the modular subgroup $\Gamma_0(\frac{n}{h}) $ by the element $\begin{bmatrix} h & 0 \ 0 & 1 \end{bmatrix} $. With $\Gamma_0(n|h)+e,f,g,… $ we mean that the group $\Gamma_0(n|h) $ is extended with the involutions $W_e,W_f,W_g,… $. If we simply add all Atkin-Lehner involutions we write $\Gamma_0(n|h)+ $ for the resulting group.