January 13th, Gallimard published Grothendieck’s text Recoltes et Semailles in a fancy box containing two books.
Here’s a G-translation of Gallimard’s blurb:
“Considered the mathematical genius of the second half of the 20th century, Alexandre Grothendieck is the author of Récoltes et semailles, a kind of “monster” of more than a thousand pages, according to his own words. The mythical typescript, which opens with a sharp criticism of the ethics of mathematicians, will take the reader into the intimate territories of a spiritual experience after having initiated him into radical ecology.
In this literary braid, several stories intertwine, “a journey to discover a past; a meditation on existence; a picture of the mores of a milieu and an era (or the picture of the insidious and implacable shift from one era to another…); an investigation (almost police at times, and at others bordering on the swashbuckling novel in the depths of the mathematical megapolis…); a vast mathematical digression (which will sow more than one…); […] a diary ; a psychology of discovery and creation; an indictment (ruthless, as it should be…), even a settling of accounts in “the beautiful mathematical world” (and without giving gifts…)”.”
All literary events, great or small, are cause for the French to fill a radio show.
The embedded YouTube above starts at 12:06, when Bourguignon describes Grothendieck’s main achievements.
Clearly, he starts off with the notion of schemes which, he says, proved to be decisive in the further development of algebraic geometry. Five years ago, I guess he would have continued mentioning FLT and other striking results, impossible to prove without scheme theory.
Now, he goes on saying that Grothendieck laid the basis of topos theory (“to define it, I would need not one minute and a half but a year and a half”), which is only now showing its first applications.
Grothendieck, Bourguignon goes on, was the first to envision the true potential of this theory, which we should take very seriously according to people like Lafforgue and Connes, and which will have applications in fields far from algebraic geometry.
Topos20 is spreading rapidly among French mathematicians. We’ll have to await further results before Topos20 will become a pandemic.
Another interesting fragment starts at 16:19 and concerns Grothendieck’s gribouillis, the 50.000 pages of scribblings found in Lasserre after his death.
Bourguignon had the opportunity to see them some time ago, and when asked to describe them he tells they are in ‘caisses’ stacked in a ‘libraire’.
Here’s a picture of these crates taken by Leila Schneps in Lasserre around the time of Grothendieck’s funeral.
If you want to know what’s in these notes, and how they ended up at that place in Paris, you might want to read this and that post.
If Bourguignon had to consult these notes at the Librairie Alain Brieux, it seems that there is no progress in the negotiations with Grothendieck’s children to make them public, or at least accessible.
Here’s a nice introduction to neural networks for category theorists by Bruno Gavranovic. At 1.49m he tries to explain supervised learning with neural networks in one slide. Learners show up later in the talk.
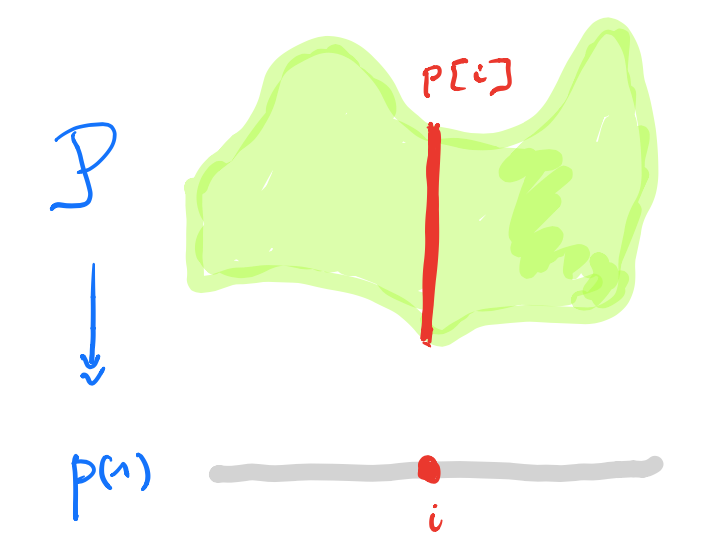
$\mathbf{Poly}$ is the category of all polynomial functors, that is, things of the form
\[
p = \sum_{i \in p(1)} y^{p[i]}~:~\mathbf{Sets} \rightarrow \mathbf{Sets} \qquad S \mapsto \bigsqcup_{i \in p(1)} Maps(p[i],S) \]
with $p(1)$ and all $p[i]$ sets.
Last time I gave Spivak’s ‘corolla’ picture to think about such functors.
I prefer to view $p \in \mathbf{Poly}$ as an horribly discrete ‘sheaf’ $\mathcal{P}$ over the ‘space’ $p(1)$ with stalk $p[i]=\mathcal{P}_i$ at point $i \in p(1)$.
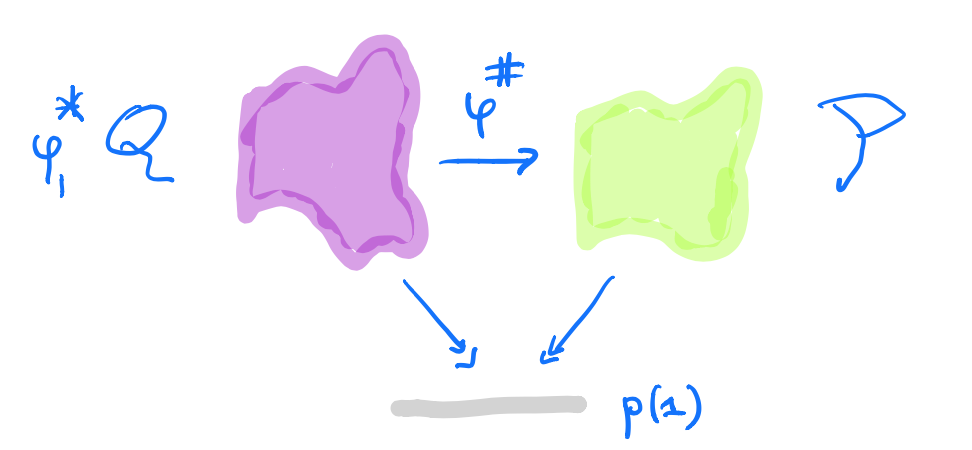
A morphism $p \rightarrow q$ in $\mathbf{Poly}$ is a map $\varphi_1 : p(1) \rightarrow q(1)$, together with for all $i \in p(1)$ a map $\varphi^{\#}_i : q[\varphi_1(i)] \rightarrow p[i]$.
In the sheaf picture, this gives a map of sheaves over the space $p(1)$ from the inverse image sheaf $\varphi_1^* \mathcal{Q}$ to $\mathcal{P}$.
But, unless you dream of sheaves in the night, by all means stick to Spivak’s corolla picture.
A learner $A \rightarrow B$ between two sets $A$ and $B$ is a complicated tuple of things $(P,I,U,R)$:
$P$ is a set, a parameter space of some maps from $A$ to $B$.
$I$ is the interpretation map $I : P \times A \rightarrow B$ describing the maps in $P$.
$U$ is the update map $U : P \times A \times B \rightarrow P$, the learning procedure. The idea is that $U(p,a,b)$ is a map which sends $a$ closer to $b$ than the map $p$ did.
$R$ is the request map $R : P \times A \times B \rightarrow A$.
Here’s a nice application of $\mathbf{Poly}$’s set-up:
Morphisms $\mathbf{P y^P \rightarrow Maps(A,B) \times Maps(A \times B,A) y^{A \times B}}$ in $\mathbf{Poly}$ coincide with learners $\mathbf{A \rightarrow B}$ with parameter space $\mathbf{P}$.
This follows from unpacking the definition of morphism in $\mathbf{Poly}$ and the process CT-ers prefer to call Currying.
The space-map $\varphi_1 : P \rightarrow Maps(A,B) \times Maps(A \times B,A)$ gives us the interpretation and request-map, whereas the sheaf-map $\varphi^{\#}$ gives us the more mysterious update-map $P \times A \times B \rightarrow P$.
$\mathbf{Learn(A,B)}$ is the category with objects all the learners $A \rightarrow B$ (for all paramater-sets $P$), and with morphisms defined naturally, that is, maps between the parameter-sets, compatible with the structural maps.
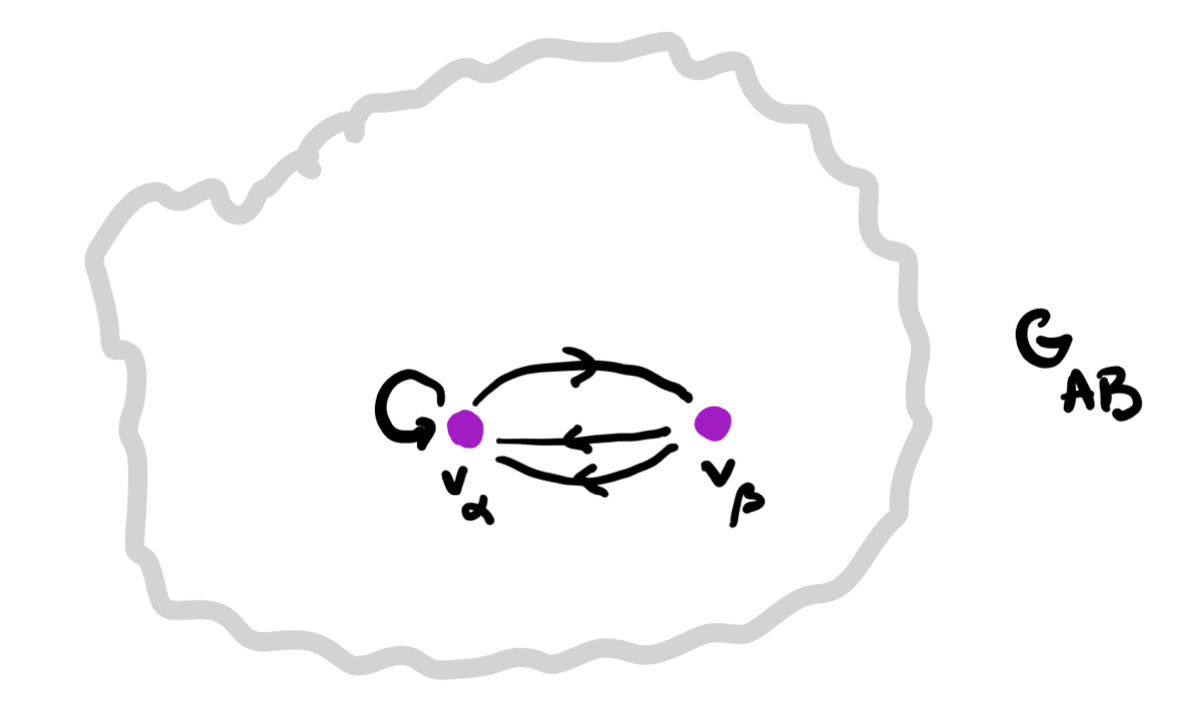
$\mathbf{Learn(A,B)}$ is a topos. In fact, it is the topos of all set-valued representations of a (huge) directed graph $\mathbf{G_{AB}}$.
This will take some time.
Let’s bring some dynamics in. Take any polynmial functor $p \in \mathbf{Poly}$ and fix a morphism in $\mathbf{Poly}$
\[
\varphi = (\varphi_1,\varphi[-])~:~p(1) y^{p(1)} \rightarrow p \]
with space-map $\varphi_1$ the identity map.
We form a directed graph:
the vertices are the elements of $p(1)$,
vertex $i \in p(1)$ is the source vertex of exactly one arrow for every $a \in p[i]$,
the target vertex of that arrow is the vertex $\phi[i](a) \in p(1)$.
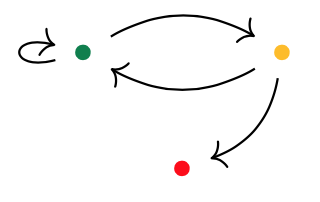
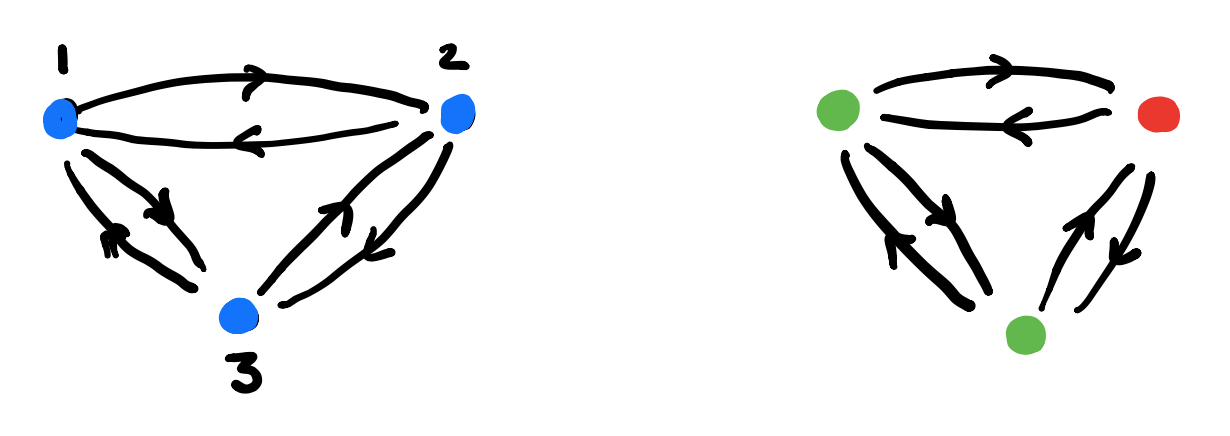
Here’s one possibility from Spivak’s paper for $p = 2y^2 + 1$, with the coefficient $2$-set $\{ \text{green dot, yellow dot} \}$, and with $1$ the singleton $\{ \text{red dot} \}$.
Start at one vertex and move after a minute along a directed edge to the next (possibly the same) vertex. The potential evolutions in time will then form a tree, with each node given a label in $p(1)$.
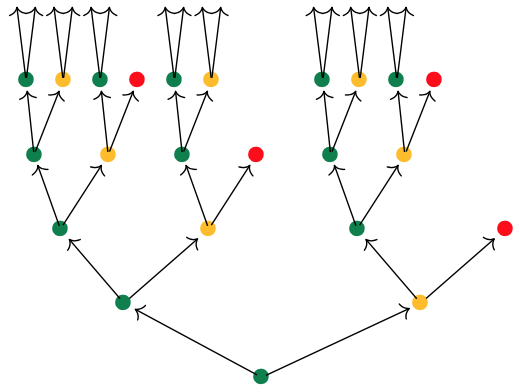
If we start at the green dot, we get this tree of potential time-evolutions
There are exactly $\# p[i]$ branches leaving a node labeled $i \in p(1)$, and all subtrees emanating from equal labelled nodes are isomorphic.
If we had started at the yellow dot we had obtained a labelled tree isomorphic to the subtree emanating here from any yellow dot.
We can do the same things for any morphism in $\mathbf{Poly}$ of the form
\[
\varphi = (\varphi_1,\varphi[-])~:~Sy^S \rightarrow p \]
Now, we have a directed graph with vertices the elements $s \in S$, with as many edges leaving vertex $s$ as there are elements $a \in p[\varphi_1(s)]$, and with the target vertex of the edge labeled $a$ starting in $s$ the vertex $\varphi[\varphi_1(s)](A)$.
Once we have this directed graph on $\# S$ vertices we can label vertex $s$ with the label $\varphi_1(s)$ from $p(1)$.
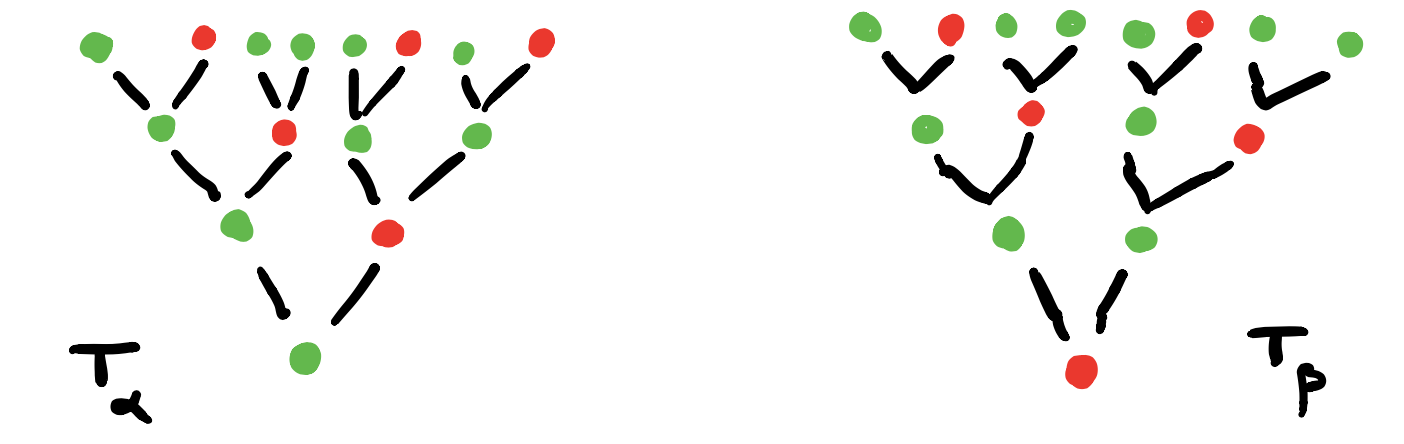
In this way, the time evolutions starting at a vertex $s \in S$ will give us a $p(1)$-labelled rooted tree.
But now, it is possibly that two distinct vertices can have the same $p(1)$-labeled tree of evolutions. But also, trees corresponding to equal labeled vertices can be different.
Right, I guess we’re ready to define the graph $G_{AB}$ and prove that $\mathbf{Learn(A,B)}$ is a topos.
In the case of learners, we have the target polynomial functor $p=C y^{A \times B}$ with $C = Maps(A,B) \times Maps(A \times B,A)$, that is
\[
p(1) = C \quad \text{and all} \quad p[i]=A \times B \]
Start with the free rooted tree $T$ having exactly $\# A \times B$ branches growing from each node.
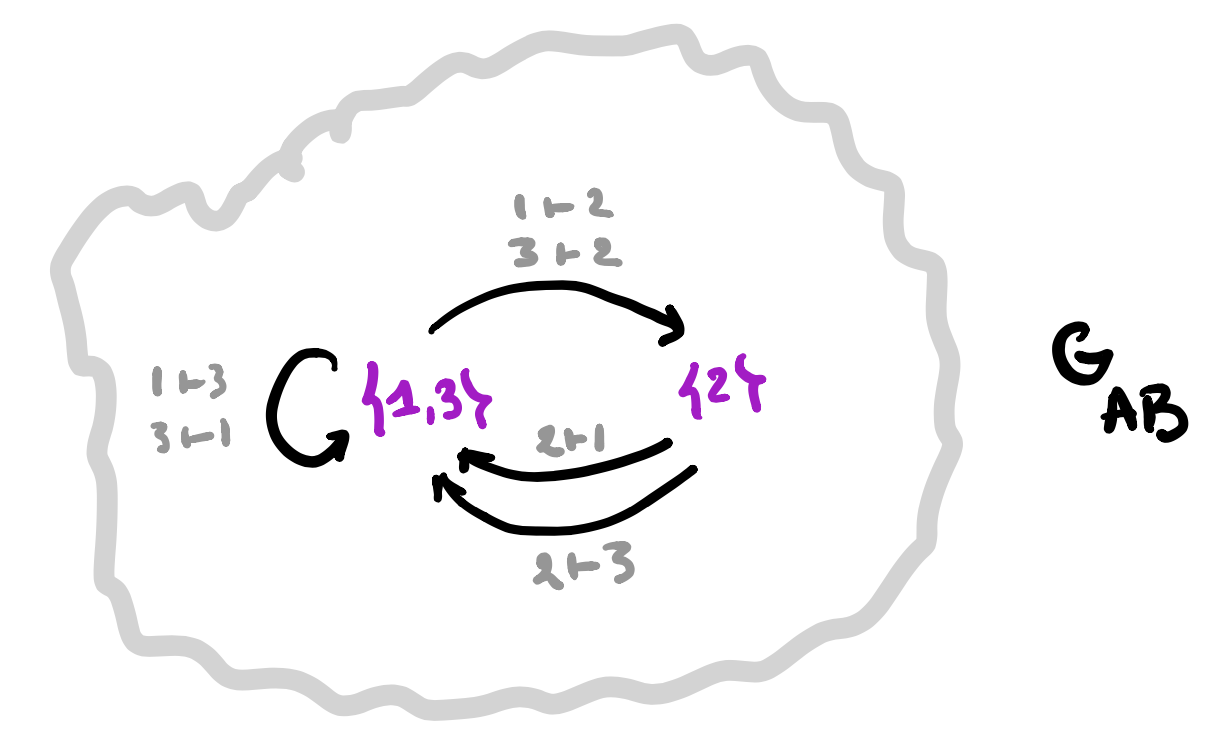
Here’s the directed graph $G_{AB}$:
vertices $v_{\chi}$ correspond to the different $C$-labelings of $T$, one $C$-labeled rooted tree $T_{\chi}$ for every map $\chi : vtx(T) \rightarrow C$,
arrows $v_{\chi} \rightarrow v_{\omega}$ if and only if $T_{\omega}$ is the rooted $C$-labelled tree isomorphic to the subtree of $T_{\chi}$ rooted at one step from the root.
A learner $\mathbf{A \rightarrow B}$ gives a set-valued representation of $\mathbf{G_{AB}}$.
We saw that a learner $A \rightarrow B$ is the same thing as a morphism in $\mathbf{Poly}$
\[
\varphi = (\varphi_1,\varphi[-])~:~P y^P \rightarrow C y^{A \times B} \]
with $P$ the parameter set of maps.
Here’s what we have to do:
1. Draw the directed graph on vertices $p \in P$ giving the dynamics of the morphism $\varphi$. This graph describes how the learner can cycle through the parameter-set.
2. Use the map $\varphi_1$ to label the vertices with elements from $C$.
3. For each vertex draw the rooted $C$-labeled tree of potential time-evolutions starting in that vertex.
In this example the time-evolutions of the two green vertices are the same, but in general they can be different.
4. Find the vertices in $G_{AB}$ determined by these $C$-labeled trees and note that they span a full subgraph of $G_{AB}$.
5. The vertex-set $P_v$ consists of all elements from $p$ whose ($C$-labeled) vertex has evolution-tree $T_v$. If $v \rightarrow w$ is a directed edge in $G_{AB}$ corresponding to an element $(a,b) \in A \times B$, then the map on the vertex-sets corresponding to this edge is
\[
f_{v,(a,b)}~:~P_v \rightarrow P_w \qquad p \mapsto \varphi[\varphi_1(p)](a,b) \]
A set-valued representation of $\mathbf{G_{AB}}$ gives a learner $\mathbf{A \rightarrow B}$.
1. Take a set-valued representation of $G_{AB}$, that is, the finite or infinite collection of vertices $V$ in $G_{AB}$ where the vertex-set $P_v$ is non-empty. Note that these vertices span a full subgraph of $G_{AB}$.
And, for each directed arrow $v \rightarrow w$ in this subgraph, labeled by an element $(a,b) \in A \times B$ we have a map
\[
f_{v,(a,b)}~:~P_v \rightarrow P_w \]
2. The parameter set of our learner will be $P = \sqcup_v P_v$, the disjoint union of the non-empty vertex-sets.
3. The space-map $\varphi_1 : P \rightarrow C$ will send an element in $P_v$ to the $C$-label of the root of the tree $T_v$. This gives us already the interpretation and request maps
\[
I : P \times A \rightarrow B \quad \text{and} \quad R : P \times A \times B \rightarrow A \]
4. The update map $U : P \times A \times B \rightarrow P$ follows from the sheaf-map we can define stalk-wise
\[
\varphi[\varphi_1(p)](a,b) = f_{v,(a,b)}(p) \]
if $p \in P_v$.
That’s all folks!
$\mathbf{Learn(A,B)}$ is equivalent to the (covariant) functors $\mathbf{G_{AB} \rightarrow Sets}$.
Changing the directions of all arrows in $G_{AB}$ any covariant functor $\mathbf{G_{AB} \rightarrow Sets}$ becomes a contravariant functor $\mathbf{G_{AB}^o \rightarrow Sets}$, making $\mathbf{Learn(A,B)}$ an honest to Groth topos!
Every topos comes with its own logic, so we have a ‘learners’ logic’. (to be continued)
Following up on the deep learning and toposes-post, I was planning to do something on the logic of neural networks.
Prepping for this I saw David Spivak’s paper Learner’s Languages doing exactly that, but in the more general setting of ‘learners’ (see also the deep learning post).
And then … I fell under the spell of $\mathbf{Poly}$.
Spivak is a story-telling talent. A long time ago I copied his short story (actually his abstract for a talk) “Presheaf, the cobbler” in the Children have always loved colimits-post.
Last week, he did post Poly makes me happy and smart on the blog of the Topos Institute, which is another great read.
If you are more the reading-type, the 273 pages of the Poly-book will also kill a good number of your living hours.
Personally, I have no great appetite for category theory, I prefer to digest it in homeopathic doses. And, I’m allergic to co-terminology.
So then, how to define $\mathbf{Poly}$ for the likes of me?
$\mathbf{Poly}$, you might have surmised, is a category. So, we need ‘objects’ and ‘morphisms’ between them.
Any set $A$ has a corresponding ‘representable functor’ sending a given set $S$ to the set of all maps from $A$ to $S$
\[
y^A~:~\mathbf{Sets} \rightarrow \mathbf{Sets} \qquad S \mapsto S^A=Maps(A,S) \]
This looks like a monomial in a variable $y$ ($y$ for Yoneda, of course), but does it work?
What is $y^1$, where $1$ stands for the one-element set $\{ \ast \}$? $Maps(1,S)=S$, so $y^1$ is the identity functor sending $S$ to $S$.
What is $y^0$, where $0$ is the empty set $\emptyset$? Well, for any set $S$ there is just one map $\emptyset \rightarrow S$, so $y^0$ is the constant functor sending any set $S$ to $1$. That is, $y^0=1$.
Going from monomials to polynomials we need an addition. We add such representable functors by taking disjoint unions (finite or infinite), that is
\[
\sum_{i \in I} y^{A_i}~:~\mathbf{Sets} \rightarrow \mathbf{Sets} \qquad S \mapsto \bigsqcup_{i \in I} Maps(A_i,S) \]
If all $A_i$ are equal (meaning, they have the same cardinality) we use the shorthand $Iy^A$ for this sum.
The objects in $\mathbf{Poly}$ are exactly these ‘polynomial functors’
\[
p = \sum_{i \in I} y^{p[i]} \]
with all $p[i] \in \mathbf{Sets}$. Remark that $p(1)=I$ as for any set $A$ there is just one map to $1$, that is $y^A(1) = Maps(A,1) = 1$, and we can write
\[
p = \sum_{i \in p(1)} y^{p[i]} \]
An object $p \in \mathbf{Poly}$ is thus described by the couple $(p(1),p[-])$ with $p(1)$ a set, and a functor $p[-] : p(1) \rightarrow \mathbf{Sets}$ where $p(1)$ is now a category with objects the elements of $p(1)$ and no morphisms apart from the identities.
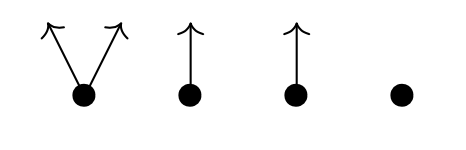
We can depict $p$ by a trimmed down forest, Spivak calls it the corolla of $p$, where the tree roots are the elements of $p(1)$ and the tree with root $i \in p(1)$ has one branch from the root for any element in $p[i]$. The corolla of $p=y^2+2y+1$ looks like
If $M$ is an $m$-dimensional manifold, then you might view its tangent bundle $TM$ set-theoretically as the ‘corolla’ of the polynomial functor $M y^{\mathbb{R}^m}$, the tree-roots corresponding to the points of the manifold, and the branches to the different tangent vectors in these points.
Morphisms in $\mathbf{Poly}$ are a bit strange. For two polynomial functors $p=(p(1),p[-])$ and $q=(q(1),q[-])$ a map $p \rightarrow q$ in $\mathbf{Poly}$ consists of
a map $\phi_1 : p(1) \rightarrow q(1)$ on the tree-roots in the right direction, and
for any $i \in p(1)$ a map $q[\phi_1(i)] \rightarrow p[i]$ on the branches in the opposite direction
In our manifold/tangentbundle example, a morphism $My^{\mathbb{R}^m} \rightarrow y^1$ sends every point $p \in M$ to the unique root of $y^1$ and the unique branch in $y^1$ picks out a unique tangent-vector for every point of $M$. That is, vectorfields on $M$ are very special (smooth) morphisms $Mu^{\mathbb{R}^m} \rightarrow y^1$ in $\mathbf{Poly}$.
A smooth map between manifolds $M \rightarrow N$, does not determine a morphism $My^{\mathbb{R}^m} \rightarrow N y^{\mathbb{R}^n}$ in $\mathbf{Poly}$ because tangent vectors are pushed forward, not pulled back.
If instead we view the cotangent bundle $T^*M$ as the corolla of the polynomial functor $My^{\mathbb{R}^m}$, then everything works well.
But then, I promised not to use co-terminology…
Another time I hope to tell you how $\mathbf{Poly}$ helps us to understand the logic of learners.