Category: web
Clearly, someone who
subscribed to your brain shouldn’t have to check the arXiv every morning only to find out
that you still haven’t posted _the_ paper s(h)e is expecting of
you, based on your recent BrainActivity…
So why not
package this into your Brain subscription? It is easy enough to get all
posts by a specific author from the archive but, unfortunately, the
arXiv doesn’t provide RSS-feeds of this information (at least, not to my
knowledge). Still, it is possible to fix this with a tiny
Perl-script.
So copy the code and adjust it replacing MyInfo
by Yours (or sligthly safer, get the arxivpost.pl
file as I had to add a few spaces to get it un-parsed) and safe it
somewhere on your system.
So how to put this to use? Btw. I know
that all of you know this by heart and that I may have given you the
(false, i swear) illusion to be fairly knowledgeable writing a
Perl-script in half an hour, but believe me, in two months (and sooner
when it’s up to me) I will have completely eradicated all this
techie-stuff from MyBrain. Then, it will take me infinitely longer to
remember/reconstruct things than it will take me now to blog this here,
so please either bear with me or go somewhere more interesting.
You’d better have Perl installed on your system, but then you have to
install extra modules from CPAN the
Comprehensive Perl Archive Network (this is to Perl what CTAN is to TeX for the mathematicians
among us). That’s pretty easy if you remember the correct commands. The
generic way to do this is by firing up your Terminal and typing things
like
iBookLieven:~ lieven$ sudo perl -MCPAN -e shell
Password: cpan shell -- CPAN exploration and modules installation
(v1.83) ReadLine support enabled cpan> install Template::Extract
and similarly for the other modules you’ll need,
LWP::Simple and XML::RSS. You may be asked questions but just go for the
default. If something goes wrong and you get a message that the module
failed to install, you have to go for a manual override…
Go to CPAN and do a search on the module’s name. You’ll
be given a list op files to download, go for the one you need and
download the souce somewhere. Then, again in Terminal do the following
routine
- cd to the downloaded and extracted directory
- perl Makefile.PL
- make
- make test
- sudo make install
Even if the test fails with
certain errors, just go ahead (it will not matter for the trivial uses
we have for these modules) and the last command is Mac OSX only (I’m
pretty certain that Linux-fanatics know what to do instead and for
Windows-diehards, well….).
Having all modules installed
you can execute the file with
perl arxivpost.pl
(assuming you created the Directory in which the program
is supposed to safe the arxivXXX.rdf file and assuming you made it
writable). That’s it. You now have your own RSS feeds of all your papers
on the arXiv which you should make for of YourBrain subscription).
Just one more thing you should do. Make this a cron
job. Check at what local time the arXiv puts online the new papers
of the day (assume it is 3am) then do a sudo crontab -e
and then add a line to the file as
5 3 * * Mon-Fri perl
/pathtowhereitis/arxivpost.pl
and your subscribers will
only have to wait 5 minutes to know whether you did it…(or not).
You can check it out either by subscribing to MyBrain or subscribing to
http://www.
neverendingbooks.org/FOAF/arxivLLB.rdf.
or
rather, I’d like to subscribe to your brain! But I figure you’d allow
this (at best) only on a ‘share-alike’ basis so let me take the first
step. Maybe you already have your newsaggregator pointed to this
weblog, but what if you could be able to follow all traces I leave on
the web (or at least those you feel like following)? It’s a great idea
which started off with a couple of posts. Like John Resig’s Life as RSS
A little while ago I began to realize just how much of my personal
information is digitally created every day. This is both scary and
enticing (to me). Scary, due to the fact that people can harness this
information for evil/marketing. Enticing because I should be able to
(theoretically) harness this information to provide a better user
experience for the people who care (me and my friends, I assume). So,
the other day I sat down and tried to figure out every accessible data
medium that I generate and have access to.
… My masterplan:
Essentially, an RSS aggregator (makes sense, nothing special) that pulls
all of my personal RSS feeds into one place and provides an overall
statistical view of the information that it contains. I may even provide
some detailed information, save for things in the ‘Personal’ category.
What I like about this is the fact that most of this information is
completely public (or is possible to make completely public) – they’re
all using common/widely available programs or tools. So, stage one: Set
up a personal life browser – stage two: Open it up for the world to play
with.
soon to be followed upp by Lost Boy’s My Life in
RDF and continued by Louche Cannon I want to subscribe
to your brain
The other day I was talking to a former
colleague and I was trying to explain how I have gradually switched to
using an assortment of social content tools as my primary mechanism for
finding relevant and authoritative information on the web. With these
tools, I can subscribe to an assortment of RSS feeds produced by people
who I trust and think of as authorities in their respective subjects. In
short, I said, “I can subscribe to their brains”.
Or at least I
can in theory! At the moment, for those of non-geekly tendencies, the
practicalities of “subscribing to somebody’s brain” are a little
daunting. If you have an RSS-aware browser or have installed one of the
useful bookmarklets provided by the likes of bloglines, then subscribing
to individual RSS feeds is relatively easy. The problem is that I might
be interested subscribing to:
– What person X is blogging
– What person X is bookmarking- on several social bookmarking sites
(e.g. del.isio.us, CiteULike, Furl)
– What person X is listening
to (e.g. AudioScrobbler)
– What person X is taking pictures of
(e.g. Flickr)
– What person X’s travel schedule is (e.g. iCal)
– What books X is reading or planning on reading (e.g. Amazon
wish lists)
The first problem is finding out what feeds person
X provides. Most of the time you have to ask them, or search through the
individual services for the person’s name. If you are dealing with a
relatively clued-in person, you might be lucky enough to find links to
their various feeds off of their home page or in the margins of their
blogs. If you are dealing with an uber-geek, then you might find this
information encoded in their FOAF file. All that seems to be missing is
the button titled “Subscribe to X’s Brain”.
While it is
still a Work In Progress (and will continue to be for some time as I’d
like to get used to the idea and explore its possibilities) you’ll find
a button to ‘subscribe to my brain’ on the buttom left. Look out for
this : 
Click on it and you’ll stare at a text-file. Save it to your desktop,
fire up your Newsaggregator (which I assume is something like NetNewsWire ). Look under
‘File’ for ‘Import Subscriptions’ and open the saved
BrainLeBruynL.opml-file. It will make a folder with name the present
date&time but you can always rename the folder to something like
‘Lieven’s brain’… Then you will look at something like
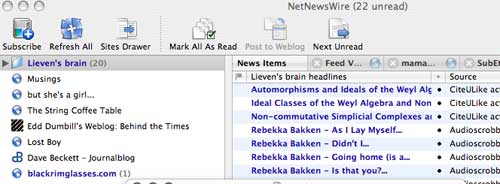 which
which
will give you a pretty good idea of what I was upto just now (posting a
few references on Cuntz and Berest to CiteULike while listening to Rebekka Bakken via iTunes. If
you’ll open up the folder you get an even clearer picture 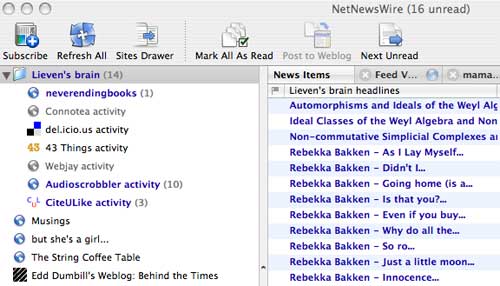 which tells
which tells
you that since last time I’ve posted three new references to CiteULike,I
listened to at least 10 new songs (Audioscrobbler only remember the last
10 ones) and that there is one new post here! You can also check on my
recent bookmarks at del.icio.us and over the next few weeks you may also
detect activity in a few other places (and I may add an arXiv scraper
just in case you think I’m not posting there anymore). Clearly, it is
up to you to unsubscribe to those regions of my brain you don’t care to
follow but the overall picture may give you a pretty accurate picture of
my present ‘state of mind’. In the coming posts I’ll take you through
the process of setting up a ‘subscribe to my brain’ for yourself and
I’ll explore (for myself) some of the possible uses of this scheme. The
ultmate aim being to see buttons like  appear on
appear on
your site as well!